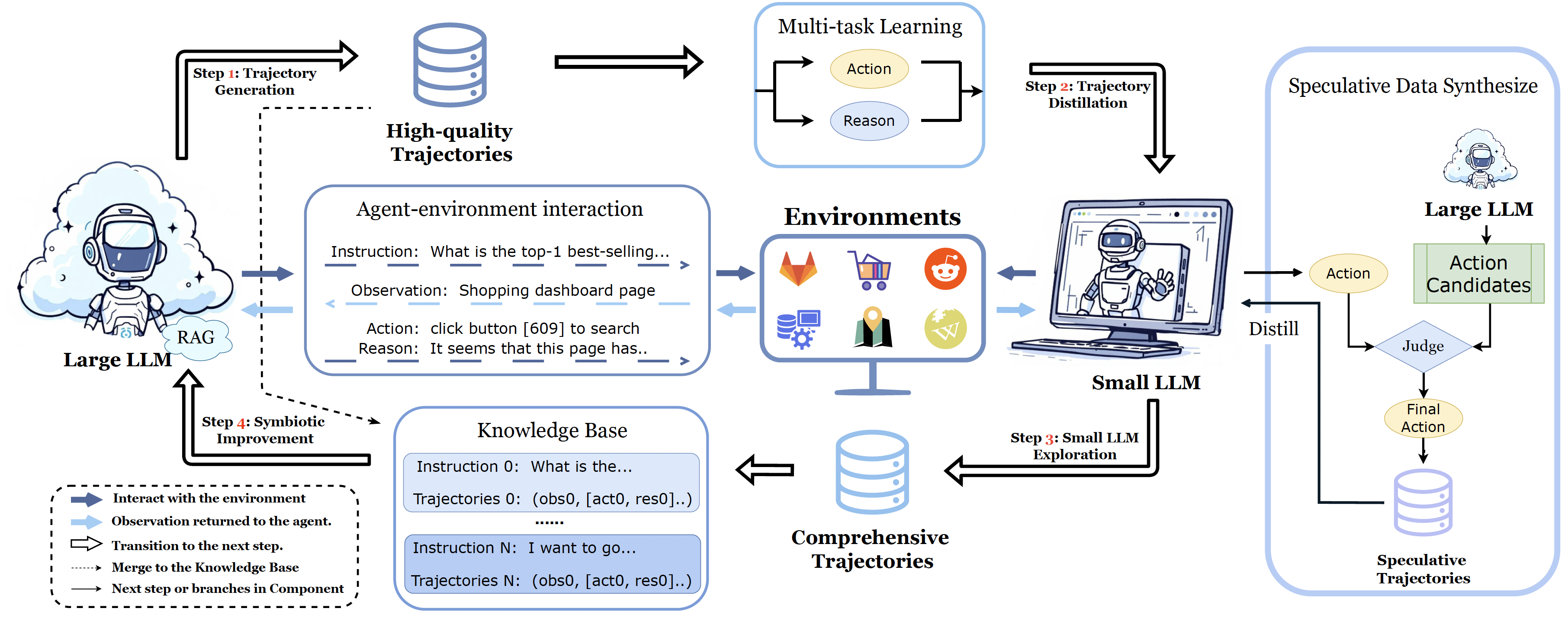
AgentSymbiotic
Our contributions can be summarized as follows:
▶ Synergistic Framework.
We present a novel framework that establishes an iterative, symbiotic cycle between large and small LLMs, enabling them to leverage their complementary strengths for mutual enhancement.
▶ Technical Innovations.
We introduce two key advancements in distillation techniques: (a) a speculative data synthesis strategy to counteract off-policy bias and (b) a multi-task learning approach to maintain reasoning capabilities.
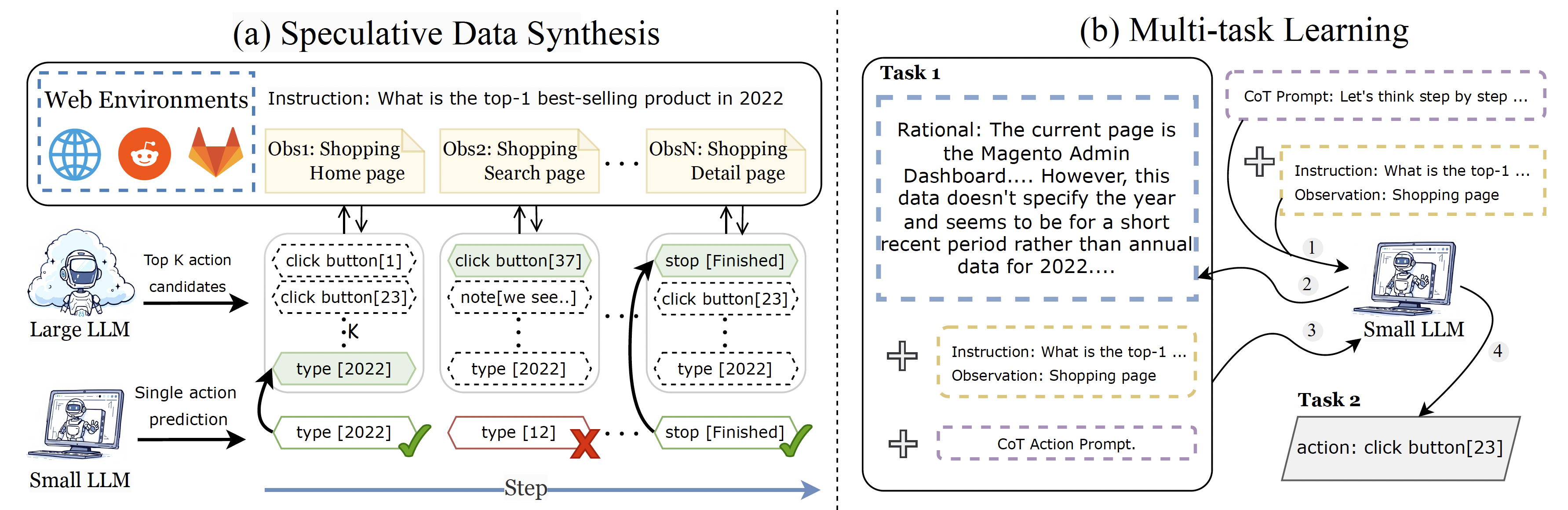
Figure 2: Overview of two key innovations in LLM distillation:
(a) Speculative Data Synthesis, which mitigates off-policy bias by leveraging both large and small LLMs. At each step, the small LLM generates an action based on the observation, while the large LLM produces a set of top-K action candidates. If the small LLM's action is within the large LLM's top-K actions, it is accepted (✓); otherwise, the large LLM's action is chosen for subsequent interactions (✗).
(b) Multi-task Learning, which enhances reasoning capabilities by training small LLM to predict both actions and rationales, enabling it to handle multiple tasks and address missing reasoning capabilities during distillation. CoT indicates Chain-of-Thought.
▶ State-of-the-art Performance.
Experiments show that on the WebArena benchmark, our method achieves state-of-the-art performance with both LLM types: the large LLM achieves 52\%, surpassing the previous best open-source 45\%, while our 8B distilled LLaMA-3 model achieves 49\%, approaching the performance of agents based on Claude-3.5.
| Method |
Model |
SR (%) ↑ |
| Learn-by-Interact | Claude-3.5 | 39.2* |
| API-Based Agent | GPT-4o | 43.9* |
| AgentOccam | GPT-4-Turbo | 45.7* |
| AgentOccam | Claude-3.5 | 48.5 |
| AgentSymbiotic | Claude-3.5 | 52.1 |
|
| Vanilla prompting | LLaMA-1B | 2.4 |
| Vanilla prompting | LLaMA-8B | 5.6 |
| Vanilla prompting | DeepSeek-R1-8B | 8.5 |
| Learn-by-Interact | Codegemma-7B | 17.9* |
| Learn-by-Interact | Codestral-22B | 28.0* |
| AgentSymbiotic | LLaMA-1B | 24.1 |
| AgentSymbiotic | DeepSeek-R1-8B | 43.6 |
| AgentSymbiotic | LLaMA-8B | 48.5 |
|
| AgentSymbiotic-Hybrid | Claude-3.5 + LLaMA-8B | 50.5 |
Comparison of final success rates (SR) among various large LLM and small LLM base agents on WebArena. Scores marked with * indicate cited scores from the corresponding papers' experiment scores.
▶ Hybrid Mode for Privacy Preservation.
We integrate a hybrid mode for privacy preservation that directs sensitive tasks to a local small LLM, ensuring that private user data remains secure.
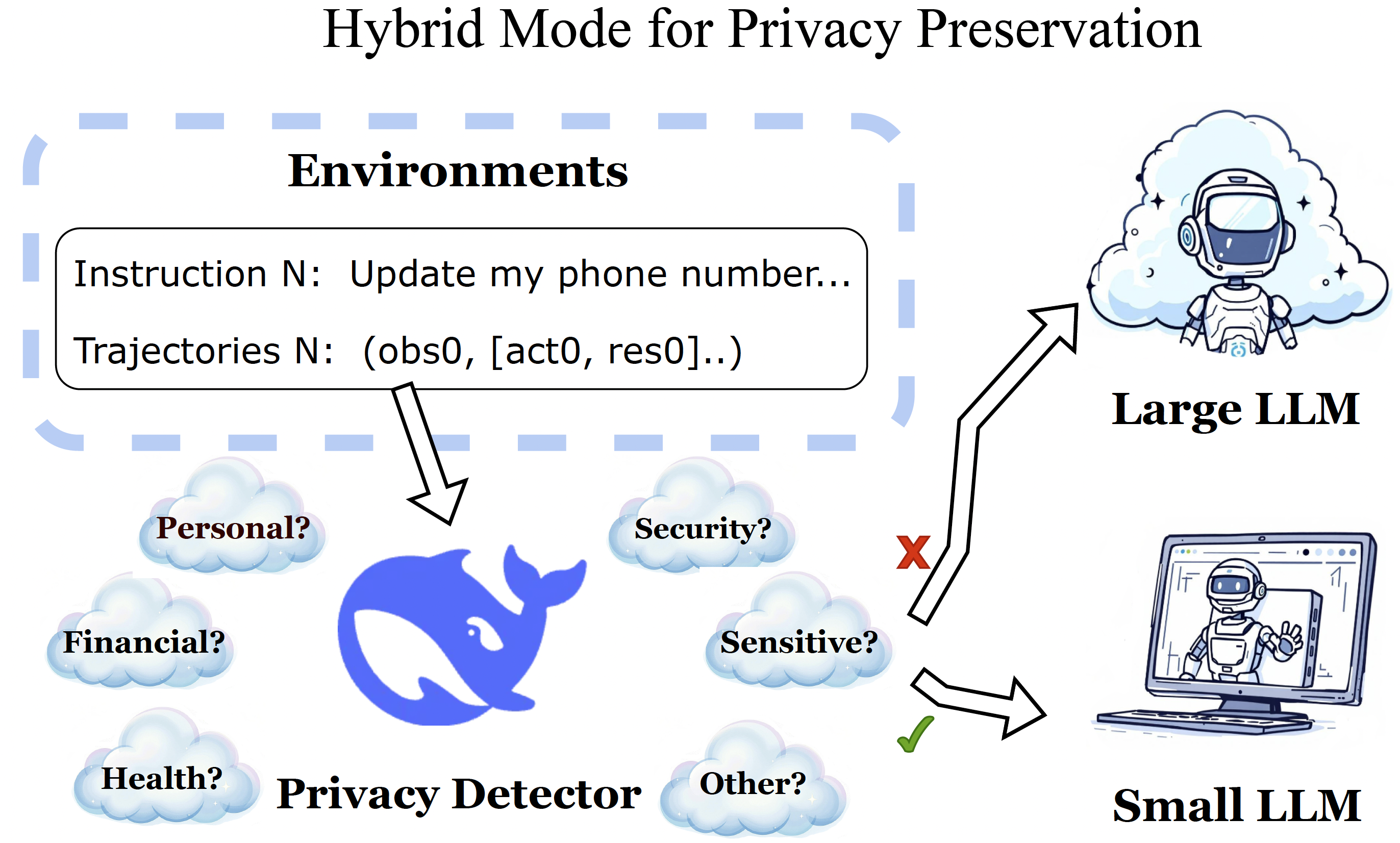
Figure 3: The Privacy Detector analyzes each step's observation and action for private data.
If detected, a local small LLM ensures confidentiality by predicting the next action and reason.
Otherwise, a cloud-based large LLM handles predictions, leveraging its superior reasoning capabilities for non-sensitive tasks.
While the large LLM offers superior reasoning and broader knowledge, many web tasks involve confidential or high-stakes information (e.g., passwords and payment details) that must be handled with care. To safeguard user privacy, we propose a hybrid mode that allows the system
to automatically switch between a local small LLM and a cloud-based large LLM.
This hybrid mode operates as follows:
Privacy Detection.
Before processing any environment observation or action, the content is scanned by a local model, which flags
potential private information—such as personally identifiable data or security tokens.
Local Processing.
If the observation or action is deemed private, the decision-making step is delegated to the small LLM deployed locally.
Cloud Processing.
If no private information is detected, the agent leverages the large, cloud-based LLM to benefit from its advanced capabilities.
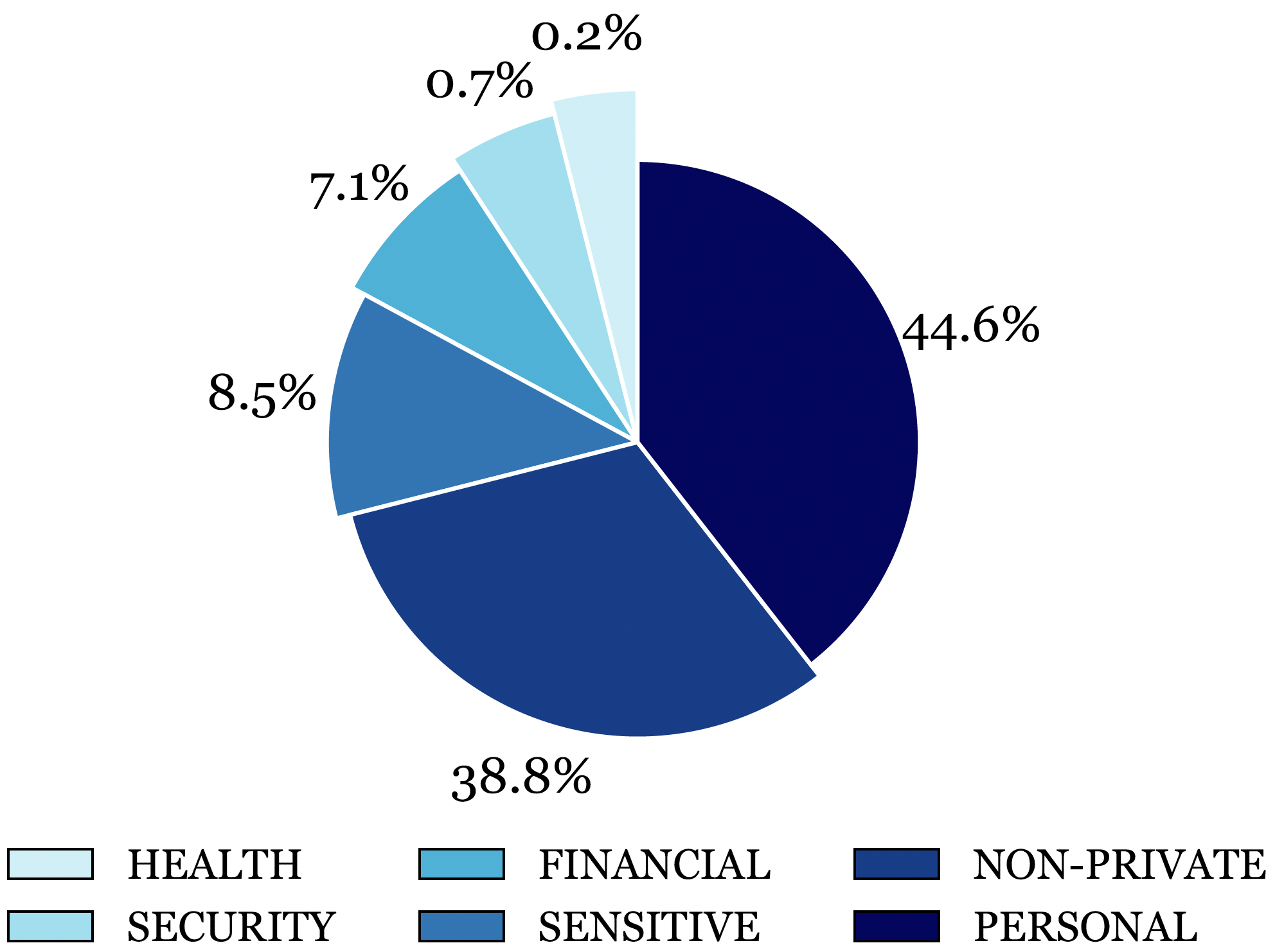
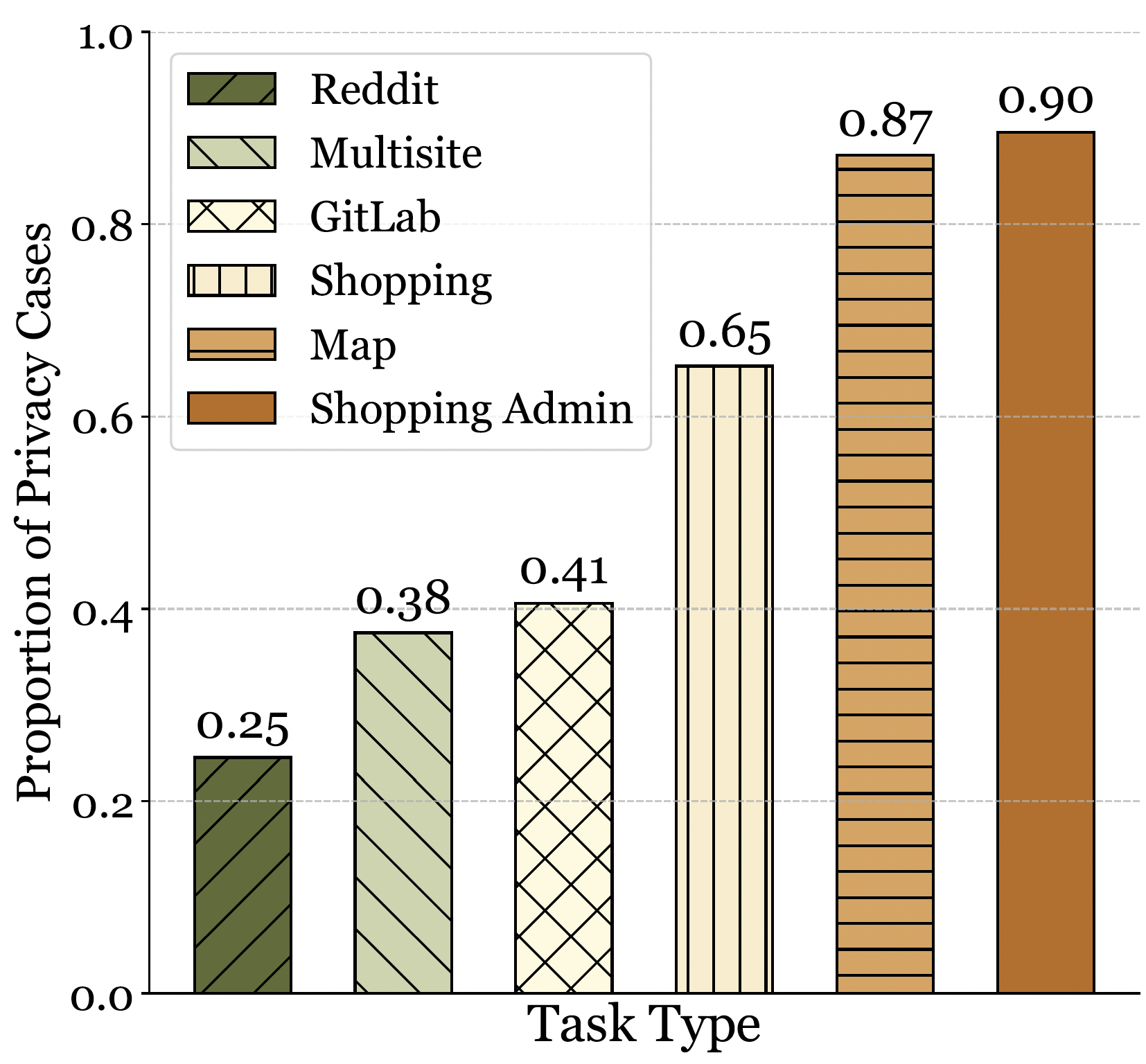
Figure 4: The Privacy Detector detects and categorizes tasks containing privacy information. We analyze their distribution to understand privacy interactions better.